Robustness of Deep Learning Model Inference
This project proves and improves the robustness of deep learning models against inference-time adversarial examples.
A unique characteristic of deep learning models is their vulnerability to malicious attacks, even when the underlying code implementations are correct. Among the various types of attacks, inference-time (or test-time) attacks have been extensively studied as they directly affect the performance and reliability of the model. These attacks craft a human-imperceptible perturbation to the test input to deceive the model into making incorrect predictions.
Test-time defenses and attacks on deep learning models have been a never-ending cat-and-mouse game. My research aims to end this game by providing deep learning model inference with well-defined and provable guarantees. I focus on the robustness verification of language models, an area previously unexplored due to the challenge of the discreteness of the inputs.
Papers: A3T (ICML2020), ARC (EMNLP2021)
Key ideas:
- Languages for describing test-time robustness for deep learning models.
- Training approaches for improving model robustness.
- An abstract interpretation technique for verifying model robustness.
Programmable perturbation space Existing work on robustness for deep learning model inference employs ad-hoc perturbations tailored to specific attacks, such as synonym substitutions. However, these perturbations do not apply to a wide range of scenarios. To address this limitation, I introduced the concept of a programmable perturbation space and designed a language for defining attacks/perturbations to input sequences for language models. The versatile language allows users to express their specific robustness requirements as user-defined string transformations and combinations. For example, it can express a perturbation that removes stop words and duplicates exclamation and question marks in a movie review. Furthermore, this language enables robustness verification and training approaches to compile and understand users’ needs seamlessly.
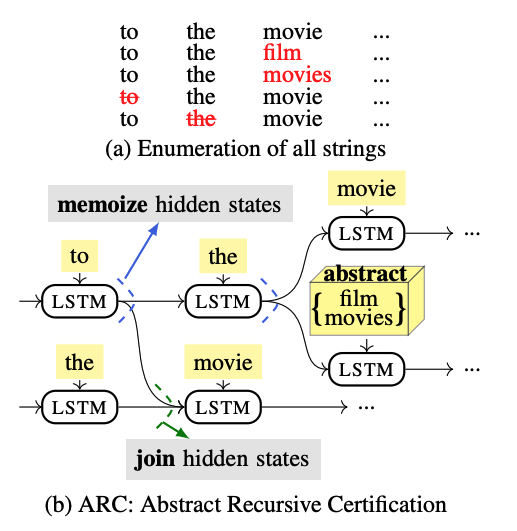
Verifying robustness of recursive models Given a robustness specification as a programmable perturbation space, my approach, ARC, generates proofs of robustness for recursive models, such as LSTMs or Tree-LSTMs. The key idea underlying ARC involves symbolically recursive memoization and abstraction of sets of possible hidden states, a task that becomes infeasible for enumeration due to its exponential growth with the input length. As ARC over-approximates the sets of all possible outcomes, it captures the worst-case scenario, thus establishing proofs for model robustness.
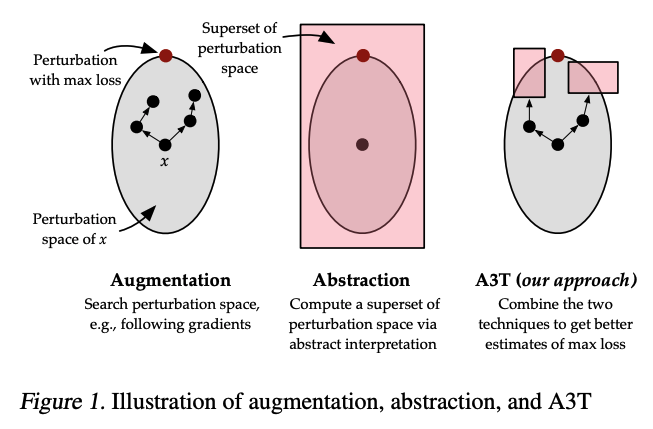
Robust training approaches When given a programmable perturbation space, the challenge of training robust models against the space lies in accurately approximating the worst-case loss. Traditional approximation methods provide loose approximations, such as the under-approximation by adversarial training or the over-approximation by provable training. To overcome this challenge, I proposed A3T, an innovative approach that approximates the worst-case by decomposing the programmable perturbation space into two subsets: one that can be explored using adversarial training and another that can be abstracted using provable training. This novel idea of decomposition has been adopted by the state-of-the-art robust training method, SABR.