Integrity of Deep Learning Model Training
This project designs certifiable defenses against data poisoning and backdoor attacks during training.
High-quality, abundant data is crucial for training deep learning models to address complex problems. However, the integrity of this data is threatened by data poisoning attacks, where an attacker can subtly modify the training set to manipulate the model’s predictions. Such attacks have been successfully utilized to surreptitiously insert backdoors into deep learning models.
This concern for data-poisoning attacks on deep learning models has led to my research on certified defenses ensuring the integrity of deep learning model training.
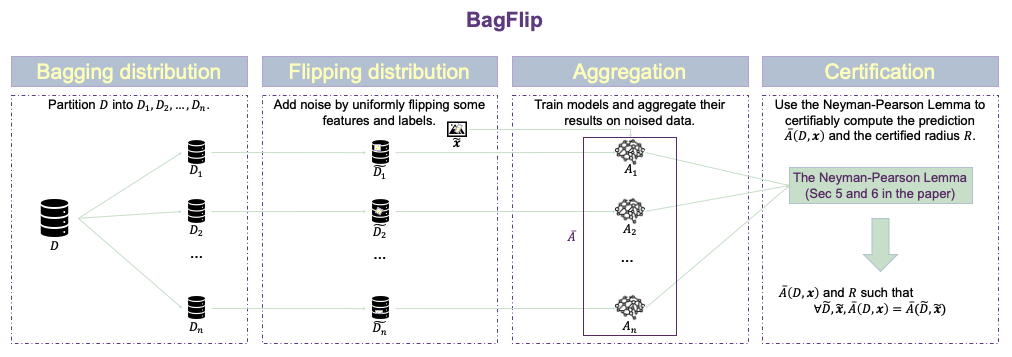
Papers: BagFlip (NeurIPS2022), PECAN (Under Submission)
Key ideas:
- Probabilistic and deterministic certified defenses against training-time attacks.
- A holistic view of handling test-time and training-time threats.
Certified defenses against test-time and training-time attacks in a holistic view I have proposed two certified defenses, BagFlip and PECAN, against data poisoning attacks that can modify both the training set and test inputs. These defenses construct a verifiable training algorithm over the original algorithm by creating an ensemble of models, each trained on subsets of the training data. These defenses adopt a holistic view of inference and training processes by regarding these processes as a closed box, abstracting away the intricate details of the training algorithm, which can pose challenges for verification techniques in establishing meaningful bounds. Leveraging this holistic view, BagFlip employs randomized smoothing to construct probabilistic proofs. In contrast, PECAN generates deterministic proofs by seamlessly integrating training-time and test-time proofs derived from corresponding techniques.